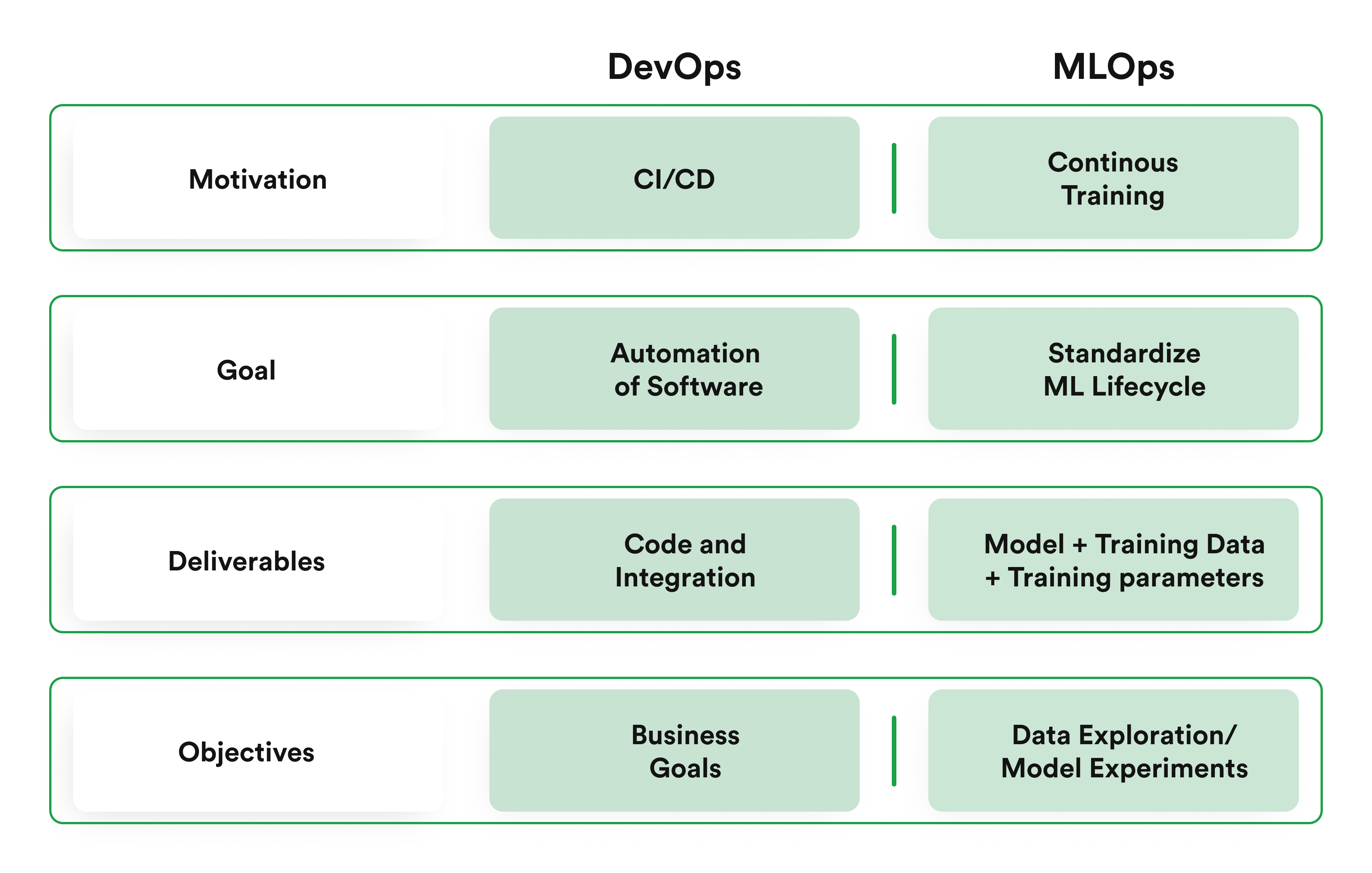
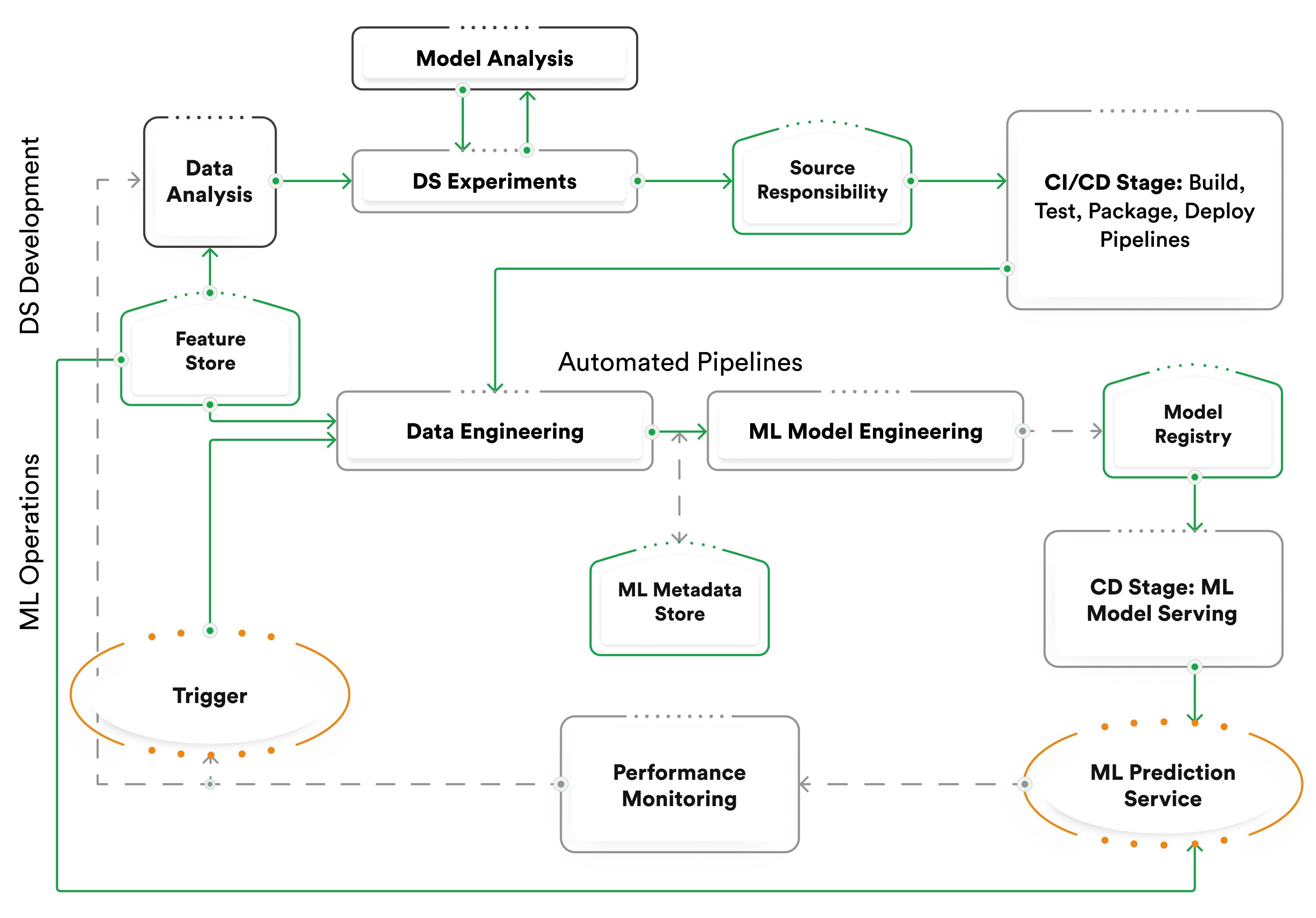
1. Track Everything with Version Control
Version control isn’t limited to source code, but should cover the entire ML pipeline. Teams can ensure full reproducibility and transparency by tracking datasets, model configurations, hyperparameters, and other important files. This means that any change, from a small tweak to a major update, can be recorded and reverted if necessary. Tools like Git and specialized systems like DVC (Data Version Control) help maintain a clear change history, foster collaboration and reduce technical debt over time.
2. Automate Your ML Workflow
Managing ML workflows manually is time-consuming and error-prone. Automating key steps like data ingestion, pre-processing, model training, testing, and deployment through a CI/CD platform like Jenkins or GitLab CI/CD can significantly reduce human effort while improving consistency. Automation allows models to be updated more frequently and reliably, smoothing the transition from development to production.
3. Keep Models Fresh with Continuous Training
Machine learning models can degrade over time as real-world data changes. Companies must implement continuous training to maintain model performance, automatically retraining when new data arrives, or model performance degrades. Integrating these retraining triggers into your CI/CD pipelines ensures that operational models stay up-to-date and adapt to evolving patterns.
4. Use Containers for Consistent Deployments
Deploying ML models can be challenging because of disparate environments. Containerization tools like Docker help package a model and its dependencies so that they always run the same way, no matter where they’re deployed. Orchestration platforms like Kubernetes make it easier to scale these deployments efficiently. Using containers, teams can eliminate the dreaded “it works on my computer” problem and simplify model management across different systems.
5. Break Code into Modular Components
A well-structured ML pipeline should be built using modular components. Organizing code into separate, reusable modules—such as data pre-processing, feature extraction, model training, and evaluation—makes it easier to maintain and scale. Modular code also reduces the risk of system-wide failures when updates are made, speeds up development cycles, and promotes collaboration by allowing different teams to work on individual components independently.
6. Keep Track of Models with a Registry
A model registry is essential for versioning and managing ML models throughout their lifecycle. Storing all model iterations in one central location allows teams to track performance, compare different versions, and deploy updates seamlessly. Tools like MLflow simplify this process by integrating into CI/CD pipelines, making deploying and managing ML models easier while keeping them reproducible and properly documented.
7. Build for Scalability from the Start
Your ML infrastructure must scale accordingly as data volumes and model complexity grow. Scalability by design means using distributed computing, autoscaling capabilities, and efficient resource management. Ensuring your infrastructure dynamically adapts to workload requirements, whether your models are running in the cloud or on-premises, reduces costs and prevents performance bottlenecks.
8. Prioritize Data Privacy and Compliance
Data protection cannot be taken lightly with strict regulations like GDPR and CCPA. Integrating strict governance practices into your ML pipelines is critical to safeguarding sensitive information. This includes encrypting data, restricting access with role-based controls, and maintaining detailed audit logs. Proactively implementing these safeguards helps organizations ensure compliance, reduce security risks, and build trust with users and stakeholders.
9. Have a Clear Incident Response Plan
No ML system is immune to problems, so a structured incident management plan is important. Teams should set up automated monitoring, logging, and alerting systems to identify issues early. A well-defined rollback strategy and post-incident analysis process help teams learn from mistakes and improve system stability. A proactive approach minimizes downtime and maintains the reliability of ML models in production.
10. Use Feedback Loops to Improve Models
The key to maintaining a high-performance ML system is continuously learning from real-world feedback. Capturing user interactions, performance metrics, and bug reports allows teams to refine models and make necessary adjustments based on real data. Establishing an automated feedback loop helps align models with business goals and ensure they remain effective as conditions change.