
ai
Everyone Wants AI, but Data Orchestration Comes First
Everyone Wants AI, but Data Orchestration Comes First Enterprise AI conversations often start in the wrong place. They focus on models, talent, or investment levels,
Now that we have established the four broad classifications of ML algorithms – supervised, unsupervised, semi-supervised, and reinforcement learning – let us delve a bit deeper and explore specific ML algorithms that are considered to be the best in 2022.
Similar to making pros and cons list as a visual aid to make the right decision, a decision tree graphically maps out outcomes for a variety of potential decisions. This supervised learning algorithm identifies the best decision to make amongst a group of possible options. It asks a question, and based on a yes/no binary answer, it keeps growing until a conclusion is reached.
The basic structure of a decision tree algorithm starts with a root node at the top of the tree. This branches into decision nodes, which are then broken down into leaf nodes. Leaf nodes contain decision outcomes.
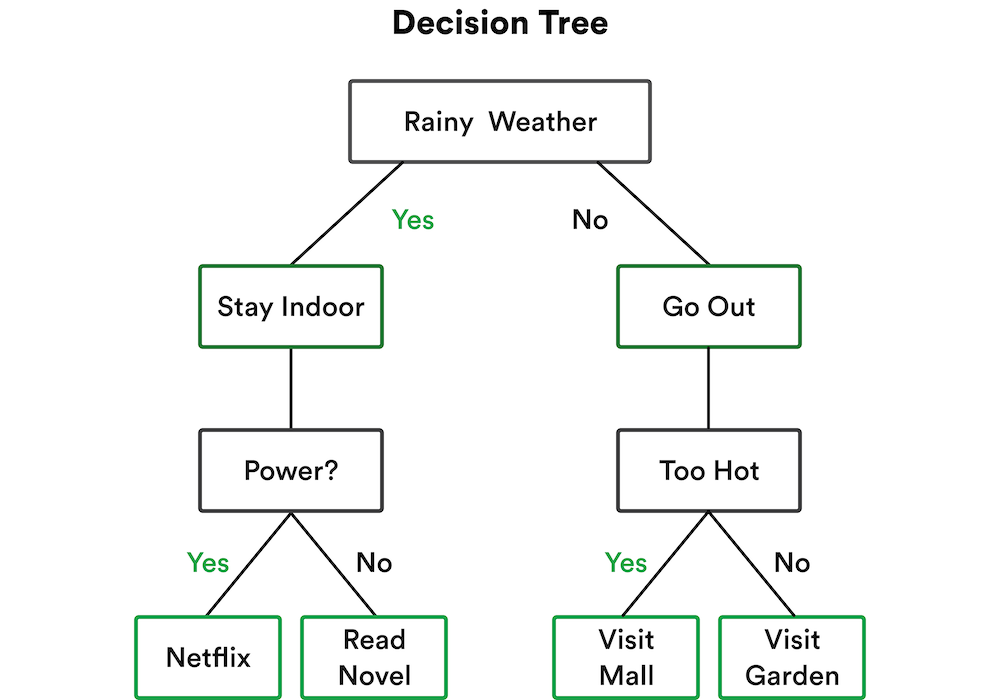
Decision tree algorithms are ideal for classification, regression, and predictive analyses. Decision trees come with some disadvantages. To reach higher levels of accuracy with decision trees, you might need the help of the next algorithm on this list.
Random Forest is a type of supervised and ensemble learning algorithm. Ensemble learning algorithms, for enhanced efficiency, use multiple models rather than just one. As the name suggests, Random Forest constructs groves of decision trees to make a final decision based on a majority vote. They are instrumental in solving regression and classification problems.
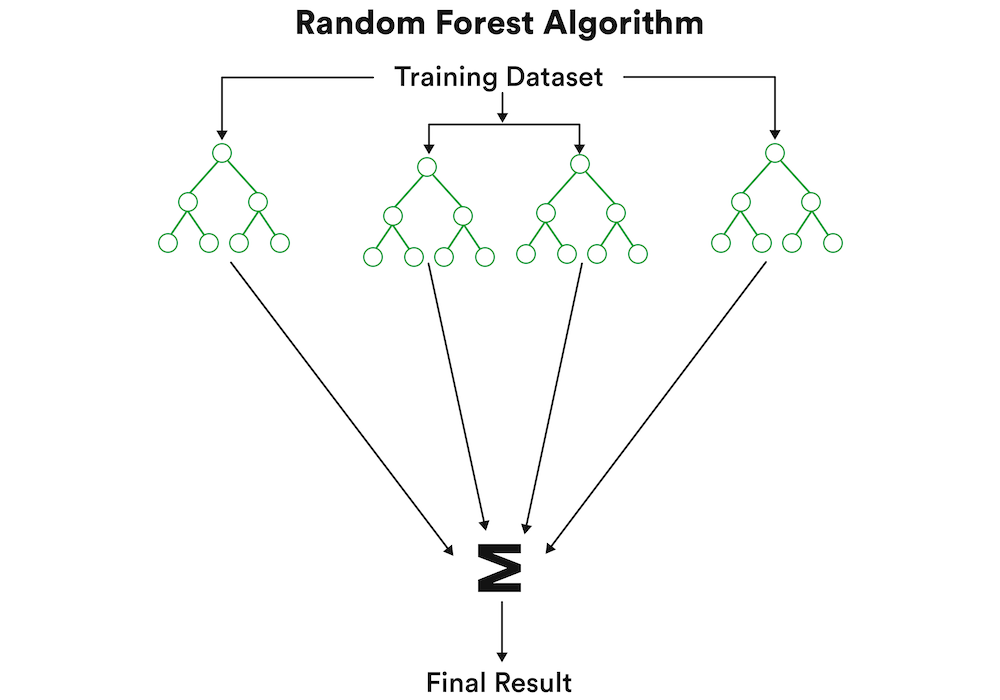
Since they utilize multiple decision trees, Random Forest algorithms are more effective than any single decision tree. Although potentially time-consuming and resource-heavy, Random Forest algorithms are generally accurate, easy to use, and efficient. They are used successfully in a range of industries, including healthcare, e-commerce, banking & finance, and marketing.
K-Means is a type of unsupervised clustering algorithm. A clustering algorithm is one where data is segmented into clusters (or K-clusters). K-Means algorithms first decide the right value for centroids (the center of a cluster) and then links other data points to those centroids based on proximity. When data is grouped with a nearby centroid, that becomes a K cluster.
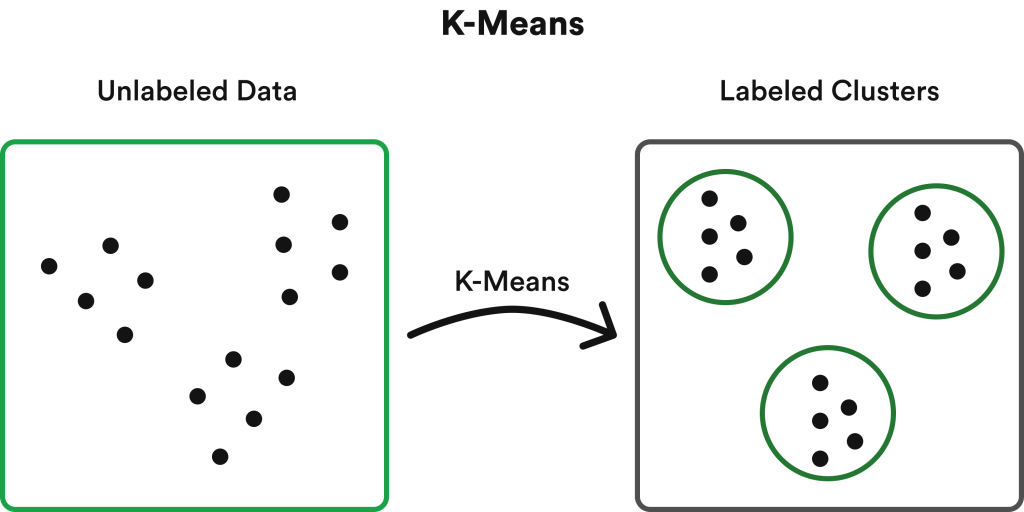
Although the structure of a K-Means algorithm might seem complicated, its common use cases will help demystify it. Use cases include customer segmentation, cyber profiling, search engine functionality, diagnostic systems, bot detection, and inventory categorization. Though it comes with limitations, the advantages of K-Means include ease, efficiency, adaptability, and scalability.
A supervised, similarity-based learning algorithm, KNN is quick, simple, and commonly used. It is relatively easy to understand as well. KNN logic is founded on the premise the neighboring data is similar, relevant data. If you listen to a particular genre of music on Spotify, the app can then see who else is listening to that genre and make suitable recommendations.
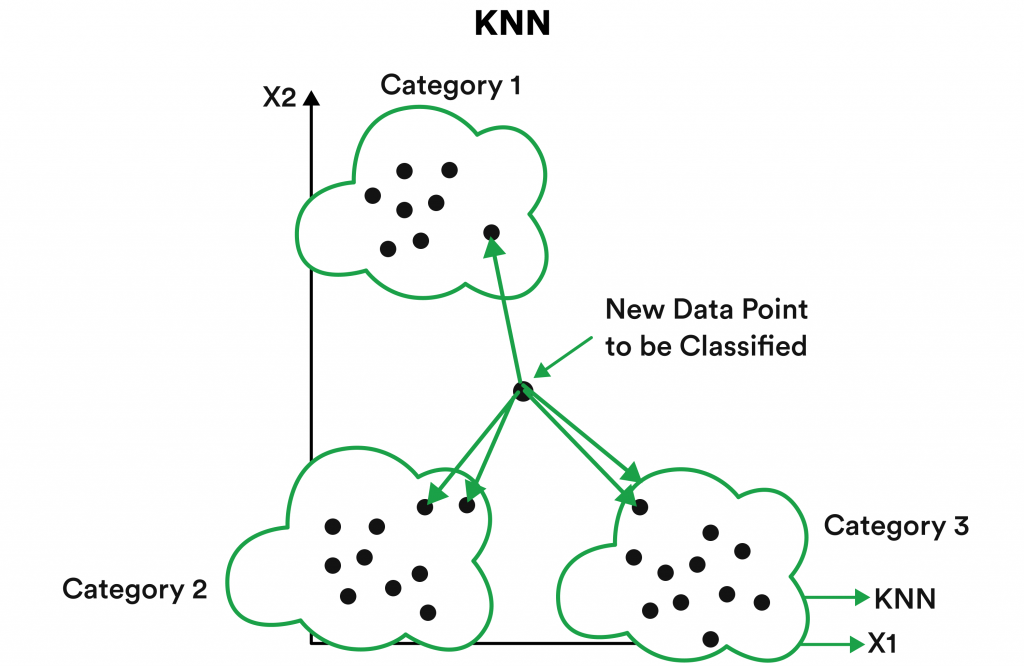
Any streaming service like Spotify or Netflix that curates media for customers without human intervention is likely using KNN algorithms. The more labeled data one has, the more efficiently KNN will function. It may require high computing power and memory, but KNN’s benefits are proven by the number of multinational companies that rely on it daily.
ANNs are perhaps the most loyal descendant of the pioneering concepts of machines that exhibit qualities of human learning. ANNs do precisely that. They try to recreate the learning functions of the human brain.
The structure of ANNs is threefold. It begins with an input layer where various forms of data are taken in. This data then goes through the processes of a hidden layer (also called a neural layer) to find patterns and logic threads. And it ends with an output later, where data that is transformed and analyzed by the hidden layer comes out as a final result or outcome.
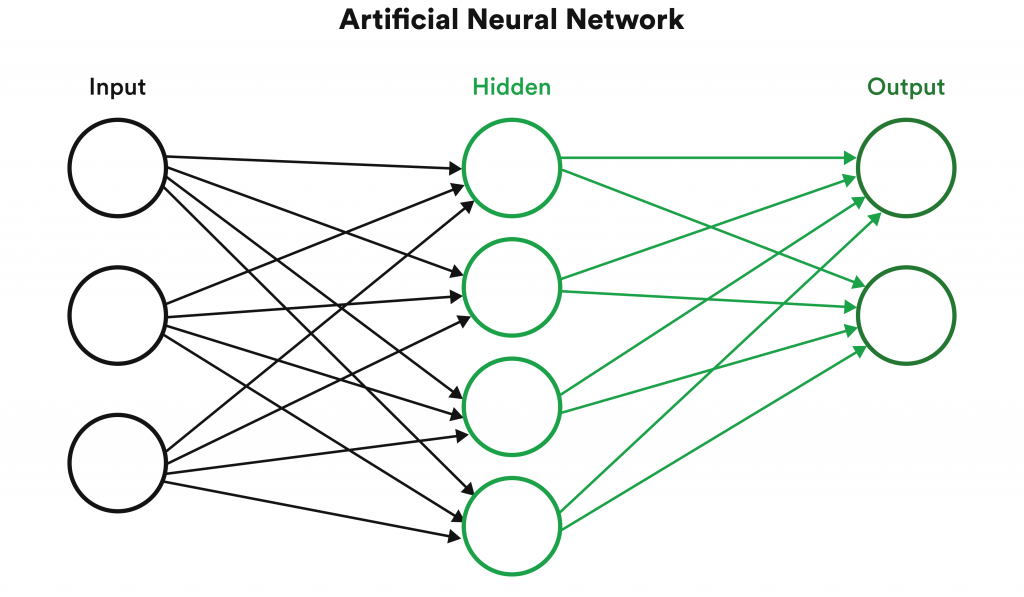
ANNs can be applied in many different ways. Some diverse use cases include marketing and advertising campaigns, healthcare (research, detection, and diagnosis), sales, forecasting stock market fluctuations, cybersecurity, facial recognition, and aerospace engineering. Advanced ANNs will likely be the building blocks of the future.
RNNs are an offshoot of ANNs. When linearity and sequence are of utmost importance, these algorithms are ideal. Every result in a particular step of an RNN algorithm is used as input for the next step. This can result in long sequential chains of data input and output. These chains can go on for any length.
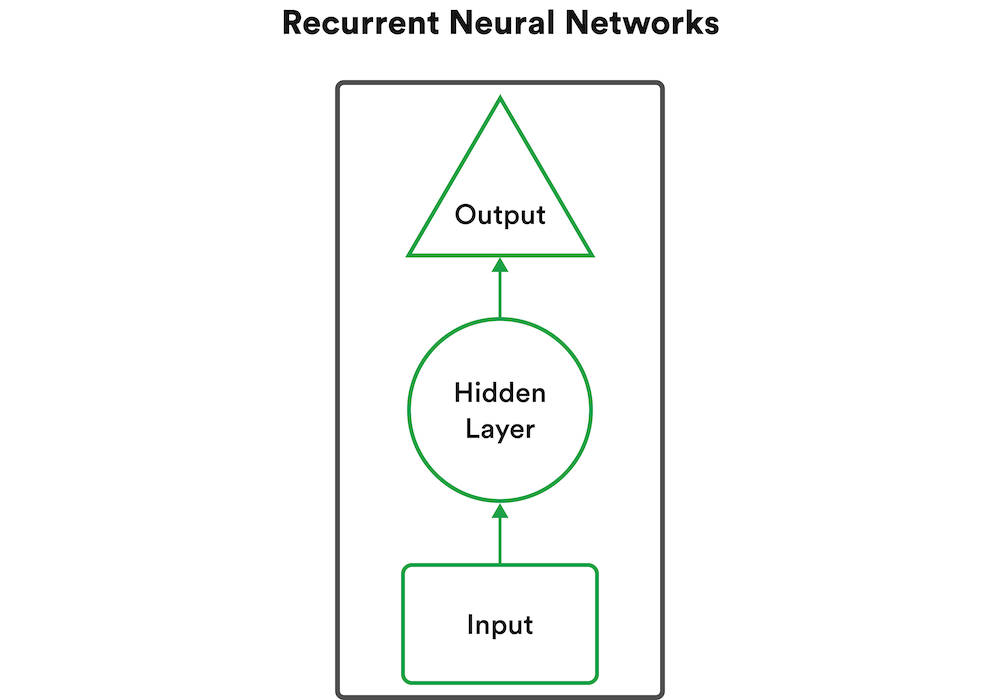
Based on how many input and output values are involved, there are a few different kinds of RNN architecture, such as one-to-one, one-to-many, many-to-one, and many-to-many, each worthy of a more nuanced, in-depth study.
These RNN architectures are particularly useful for applications that will change the future, including speech recognition, text generation, automatic language translations, image recognition, video tagging, media and art composition, and various predictive systems across industries.
This algorithm falls under a category called explanatory algorithms. An explanatory algorithm, as its name suggests, goes beyond merely predicting an outcome based on data. It is used to learn more about how or why a particular decision was made. It explores relationships between data points within models, between inputs and outputs.
Let’s use a simple example to understand linear regression. You own a plot of land that’s worth a specific price (X), and you want to sell it at market value (Y). In this case, X would be called the independent variable, and Y would be the dependent variable. Linear regression algorithms would mine relevant labeled datasets to establish a logical relationship between X and Y.
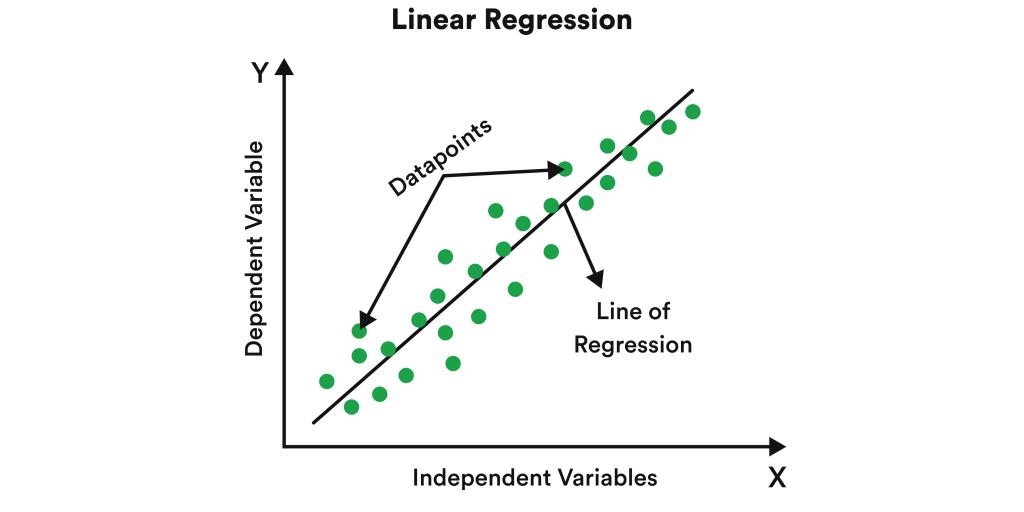
Use cases for linear regression algorithms include risk analysis in financial services and insurance, stock market predictions, sales forecasting, user/consumer behavior predictions, and understanding the outcomes of marketing campaigns. Linear regression is not a one-size-fits-all algorithm, but it can transform businesses when used correctly.
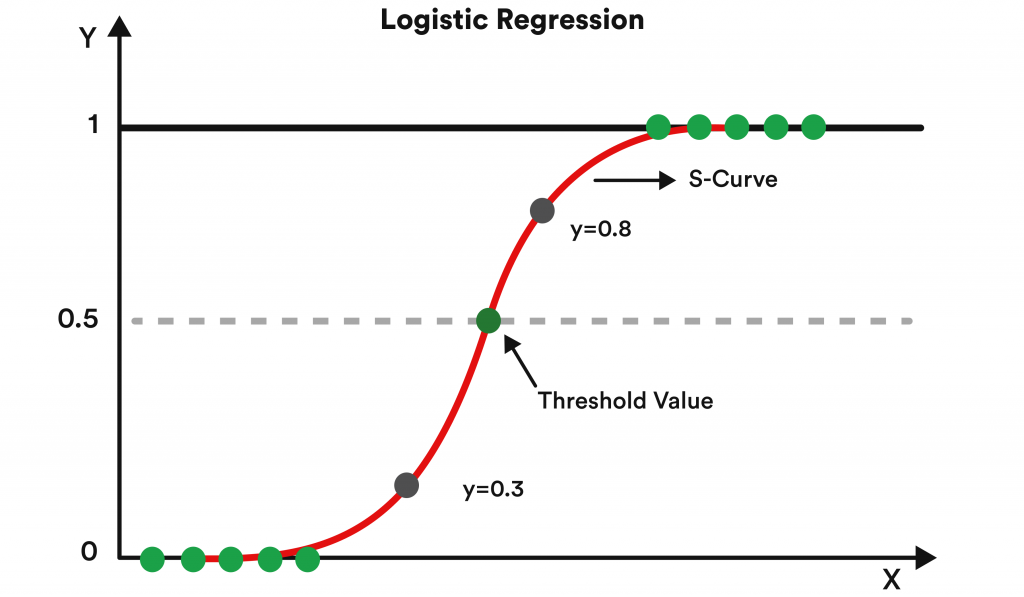
Logistic regression is another example of a supervised, explanatory algorithm. Unlike linear regression, which is fundamentally a regression model, logistic regression is a classification model.
A linear regression draws a logical map between an independent and dependent variable, and the dependent variable can have a continuous numerical value. Logistic regression, on the other hand, will only have a binary value for its dependent variable – basically, a 0/1 or yes/no kind of result.
Like many other algorithms on this list, logistic regression can be better understood by looking at how it’s applied in various industries. Healthcare is one of the greatest employers of this algorithm because binary answers are always needed in this field. So is education, where universities might filter out unqualified candidates by making a yes/no assessment.
Linear regression and logistic regression are prime examples of explanatory algorithms. Sometimes, there is a need to go beyond just being predictive. Occasionally, we need to be able to justify why and how a prediction is made.
Naïve Bayes is a probabilistic algorithm that derives from the Bayes Theorem. It is primarily used to deal with classification challenges, both binary and multiclass. The Bayes Theorem determines conditional probability by calculating the values of other probabilities, like events or occurrences, that are in proximity.
Naïve Bayes presupposes that each data attribute is independent of the other and equally important when determining an outcome. These algorithms are versatile, easy to deploy, quick, and highly accurate.
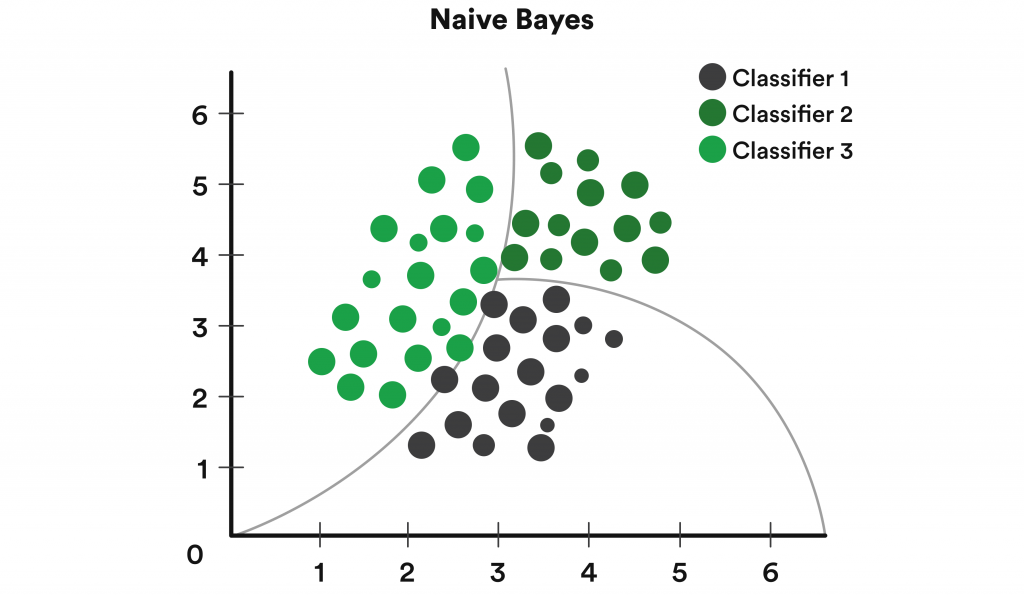
Use cases of Naïve Bayes include real-time predictions and forecasting, recommendation systems, and document and article classification. Document classifications with Naïve Bayes algorithms can be incredibly beneficial and potentially transformative for industries like (but not limited to) healthcare, supply chain, banking, finance, and various sciences.
PCA is an unsupervised dimensionality reduction algorithm. Dimensionality reduction algorithms are designed to tackle the issue of too many variables in a dataset. A dataset with thousands of variables can be a challenge. What PCA algorithms do is take those variables and transform them into smaller, compressed datasets without losing much vital information.
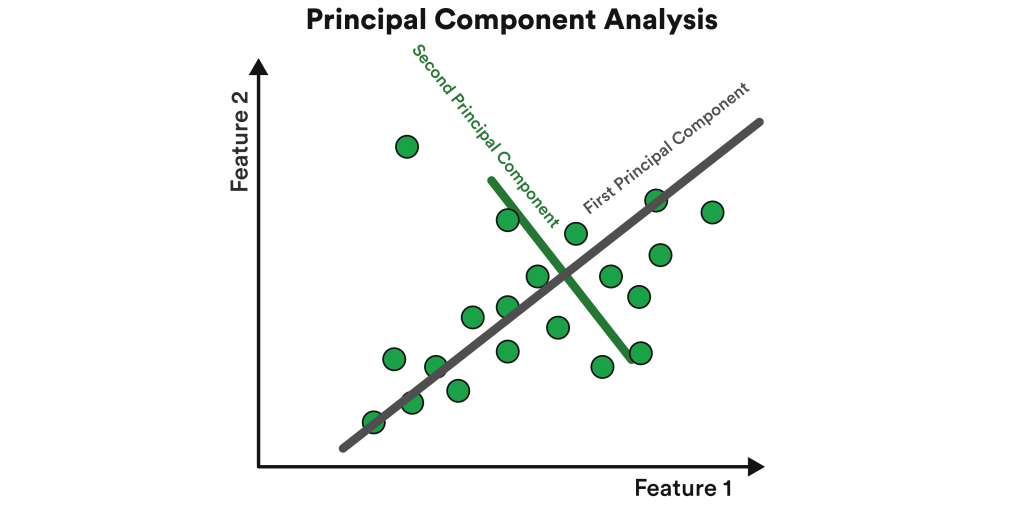
PCA has use cases in healthcare, cybersecurity, facial recognition, image compression, banking and finance, and sciences, just to name a few. Benefits primarily revolve around cleaning up large volumes of data to eliminate extra fat and redundancies. They are also cost-effective, efficiency-driven, and a tool to visualize and map out data with greater clarity.
Everyone Wants AI, but Data Orchestration Comes First Enterprise AI conversations often start in the wrong place. They focus on models, talent, or investment levels,

rinf.tech’s Databricks Partnership for Data & AI Platform Engineering in Regulated Enterprises Enabling Governed, Production-Ready Data & AI Operations rinf.tech customers gain access to production-ready Data and AI platforms,

The Hard Part of AI Starts After the Demo Works Enterprise investment in artificial intelligence continues to accelerate. Recent McKinsey surveys show that more than