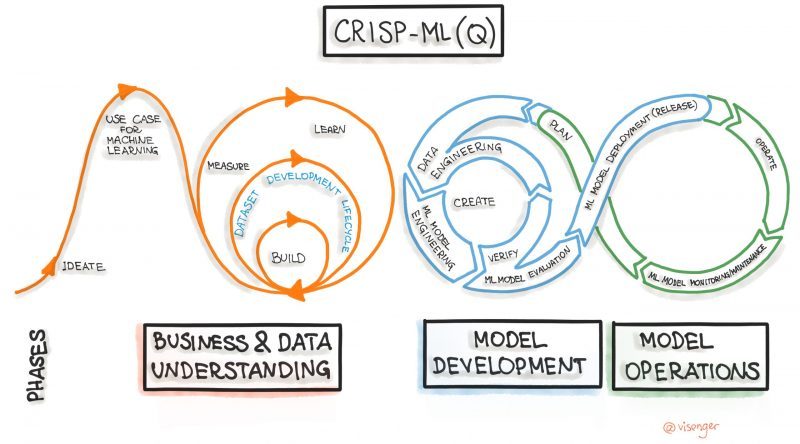
The selection and application of software delivery methodologies play a crucial role in the success of machine learning projects. Given ML initiatives’ unique challenges and requirements, it’s imperative to choose methodologies that facilitate flexibility, collaboration, and continuous improvement.
Traditional vs. Agile Methodologies
Traditional software development methodologies like the Waterfall model follow a linear and sequential approach. This model is characterized by distinct phases such as requirements, design, implementation, testing, deployment, and maintenance, with each phase completed before the next begins. While this approach offers simplicity and predictability, it tends to be rigid, making it difficult to accommodate changes once the project is underway. In the context of ML projects, where experimentation and iterative refinement are key, the Waterfall model can limit flexibility and responsiveness.
Agile methodologies, on the other hand, prioritize flexibility, customer collaboration, and responsiveness to change. Agile approaches break the project into smaller, manageable increments or sprints, allowing teams to adapt and evolve their strategies based on ongoing feedback and discoveries. This iterative process is particularly beneficial for ML projects, which often involves exploring different models, algorithms, and data sets to optimize performance.
Benefits of Agile for ML Projects
Flexibility and Adaptability: Agile methodologies allow ML teams to adapt to new findings, incorporate feedback, and pivot strategies as needed, which is essential given the experimental nature of ML projects.
Enhanced Collaboration: By encouraging regular communication among cross-functional teams and stakeholders, Agile methodologies foster a collaborative environment conducive to innovation and problem-solving in ML projects.
Incremental Delivery: Agile’s focus on delivering working software in small increments allows for early and frequent demonstrations of progress. This helps validate the direction of the ML project and builds stakeholder trust and engagement.
Risk Management: Agile methodologies facilitate early identification of issues, allowing teams to address challenges before they escalate. This is crucial for ML projects, where data or algorithmic challenges can significantly impact outcomes.
Adapting Agile for ML Project Delivery
While Agile offers significant benefits for ML projects, adapting it to these initiatives’ specific needs can further enhance its effectiveness. Here are some adaptations for ML projects:
Integration of Data Science and Software Development Processes: ML projects require close collaboration between data scientists and software engineers. Tailoring Agile practices to facilitate this integration can help streamline the development, testing, and deployment of ML models.
Flexible Sprint Goals: Given the exploratory nature of ML work, defining sprint goals in terms of learning objectives or experimental outcomes rather than fixed deliverables can provide the necessary flexibility to accommodate the iterative experimentation and refinement of ML models.
Emphasis on Technical Excellence: Agile methodologies for ML projects should place a strong emphasis on technical excellence, including practices like continuous integration and continuous deployment (CI/CD), automated testing, and robust version control for both code and data. These practices are essential for managing the complexity and ensuring the quality of ML solutions.
Adaptive Planning for Uncertainty: ML projects often face data quality, model performance, and operational integration uncertainties. Incorporating adaptive planning practices, such as regular retrospectives and planning sessions to reassess and adjust project plans, can help teams navigate these uncertainties effectively.
Crisp-DM
It’s recommended the ML development teams follow a Cross-Industry Standard Process for Data Mining (CRISP-DM) – the most widely-used analytics model and an open standard process model that describes common approaches used by data mining experts.
The components of the CRISP-DM methodology can serve as the main anchors and functional features of your project.
Let’s go through them briefly:
Business understanding: This phase focuses on understanding the overall project requirements, goals, and defining business metrics. This step also assesses the availability of resources, risks and contingencies, and conducts a cost-benefit analysis. In addition, core technologies and tools are chosen at this stage.
Data understanding: Data is a core part of any machine learning project. Without data to learn from, models cannot exist. Unfortunately, accessing and using data can take a very long time in many companies due to rules and procedures.
In this phase, the focus is on identifying, exploring, collecting, and analyzing data to achieve the project goal. This step includes identifying data sources, accessing data, creating data storage environments, and preliminary data analysis.
Data preparation: Even after the necessary data has been obtained, it is likely that it will need to be cleaned or transformed as it moves through the enterprise. In this step, the dataset is prepared for modeling; it includes subtasks of data selection, cleansing, formatting, integration, and data construction and builds data pipelines for ETL (extract, transform, load). The data will be changed several times. Understanding the processes involved in preparing these proposed subtasks is necessary for effective model building.
Modeling: After preparing the data, it is time to build and evaluate various models based on several different modeling techniques. This step consists of choosing modeling methods, developing features, creating a test project, building and evaluating models. The CRISP-DM manual suggests “repeat building and evaluating the model until you believe you have found the best one(s).”
Evaluation: The evaluation and analysis discussed above focus on evaluating the technical model. The Evaluation phase is broader as it assesses which model best fits the business objectives and the baseline. The subtasks in this phase evaluate the results (improving the model, performance metrics), analyze the processes, and determine the next steps.
Deployment: Your deployment strategy defines the complexity of this stage that includes deployment planning, monitoring and maintenance, final reporting, and validation.
Suggested sub-tasks include:
- Building an application,
- Deploying for quality assurance (QA),
- Automating the data pipeline,
- Performing Integration Testing, and
- Deploying to production.