
ai
Everyone Wants AI, but Data Orchestration Comes First
Everyone Wants AI, but Data Orchestration Comes First Enterprise AI conversations often start in the wrong place. They focus on models, talent, or investment levels,
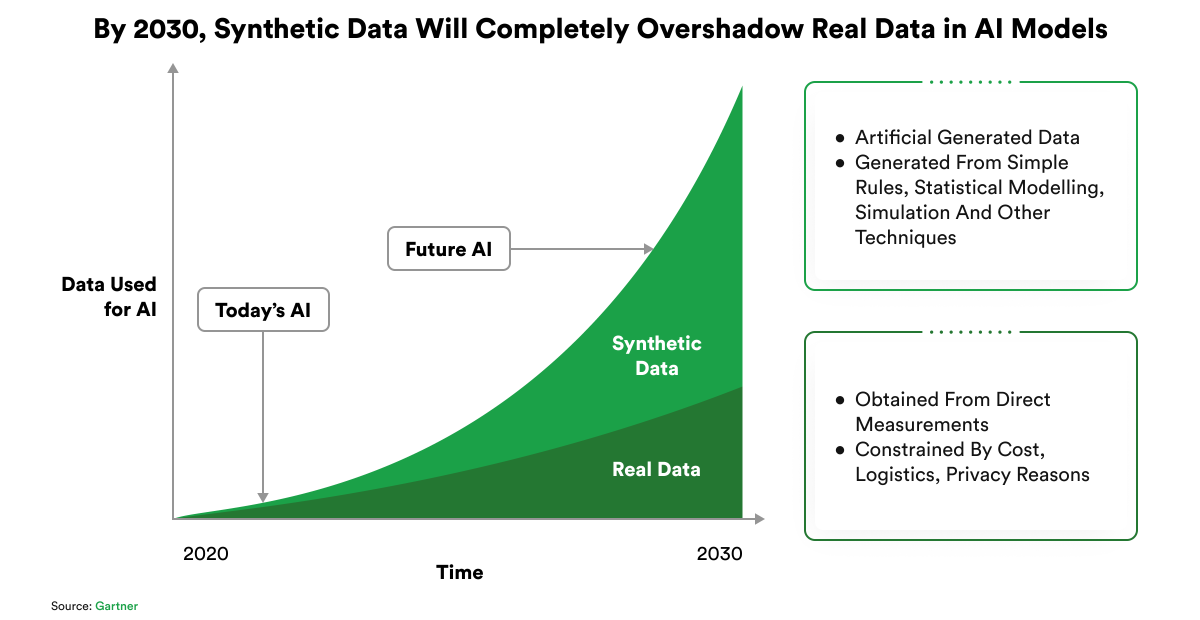
The synthetic data market is on an upward trajectory, with predictions indicating substantial growth. According to recent reports, the synthetic data generation market is expected to reach $2.1 billion by 2028. This growth is fueled by the increasing adoption of AI and Machine Learning technologies across various industries that rely heavily on large and diverse datasets for training and validation.
This article delves into the intricacies of synthetic data generation, highlights its diverse applications across industries, and examines the challenges and ethical implications accompanying its use.
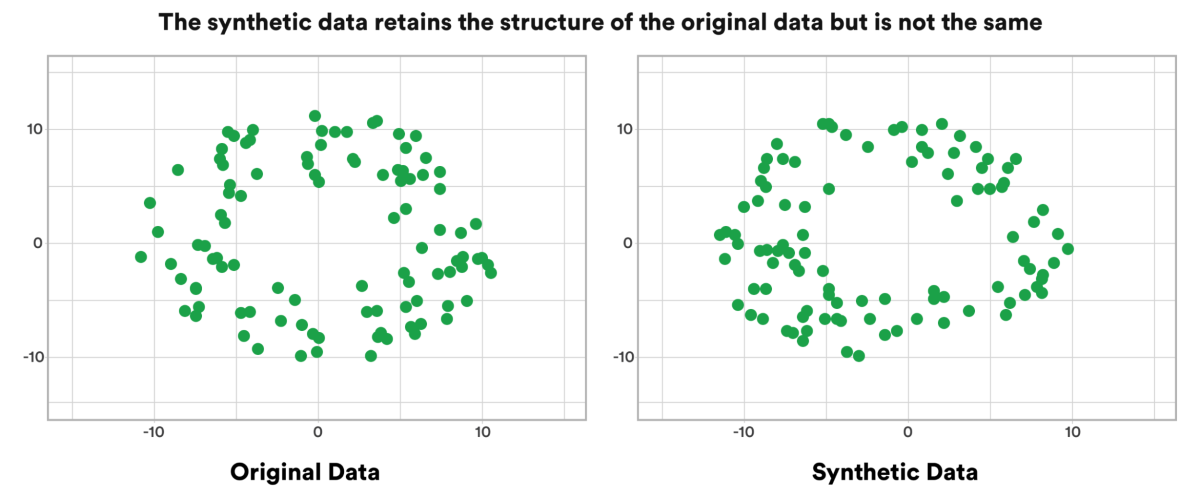
Synthetic data is artificially generated data that mimics real-world data in its statistical properties and patterns but is not derived from actual events or observations. Unlike real data collected from real-world scenarios, synthetic data is created using algorithms, models, and simulations. This data is designed to replicate the behavior and characteristics of real data, making it useful for a variety of purposes, including training AI and machine learning models, testing software, and conducting simulations.
Synthetic data offers several advantages, such as avoiding privacy concerns, reducing the cost and time associated with collecting real data, and enabling the generation of large, diverse datasets for training and testing. It is particularly valuable in situations where real data is scarce, sensitive, or difficult to obtain. However, the quality and accuracy of synthetic data are critical to ensure it effectively serves its intended purpose.
Generating synthetic data involves various complex methods, each designed to produce data that accurately mirrors the properties and patterns of real-world data.
Such methods typically involve manually crafting data by defining specific rules and parameters. This approach is often used when the data requirements are straightforward and well-understood, allowing for controlled and precise data generation.
One of the most advanced techniques is Generative Adversarial Networks (GANs). GANs consist of two neural networks—the generator and the discriminator—that work in tandem to create realistic synthetic data. The generator creates data samples while the discriminator evaluates their authenticity, leading to continuous improvements until the synthetic data is nearly indistinguishable from real data. This method is particularly effective for creating high-quality image and video data, which is essential for computer vision and autonomous driving fields.
This method generates data by encoding real data into a latent space and then decoding it back, allowing new data samples with similar properties to be generated.
This statistical approach models the dependencies between variables using copulas, enabling the generation of data that retains the original data’s statistical characteristics.
These models, often used in natural language processing, can generate synthetic data by understanding and replicating complex patterns in the data.
These include machine learning techniques tailored to specific data generation needs, ensuring the synthetic data reflects the necessary complexity and variability.
Another notable method is statistical modeling, which involves using statistical techniques to create synthetic datasets that preserve the statistical characteristics of the real data. This approach is widely applied in generating tabular data, making it valuable for industries such as finance and healthcare, where tabular datasets are prevalent. By modeling the distributions, correlations, and other statistical properties of the real data, synthetic data generated through statistical modeling can train machine learning models without compromising data integrity or privacy.
These models simulate agents’ interactions (individuals, entities, etc.) to generate data that mirrors the behavior and outcomes of complex systems. This approach is particularly useful for creating data in scenarios where interactions drive the outcomes.
Rule-based systems also play a significant role in synthetic data generation. These systems generate data based on predefined rules and patterns, ensuring that the synthetic data adheres to specific constraints and conditions. This method is particularly useful in applications where the data must follow strict regulatory or operational guidelines. For example, synthetic data can be generated in the healthcare sector to simulate patient records while ensuring compliance with HIPAA regulations.
The quality and representativeness of synthetic data are crucial for its effectiveness. Poor-quality synthetic data can lead to inaccurate models and flawed analyses. Hence, maintaining high data quality is paramount, ensuring the synthetic data accurately reflects the variability and nuances of the real-world data it aims to replicate. Tools and platforms like DataWizz, MOSTLY.AI, and Synthesized have emerged as leaders in this space, providing advanced solutions for generating high-fidelity synthetic data. These platforms leverage cutting-edge technologies to produce diverse and representative datasets that can be used across various applications, from AI training to data privacy compliance.
Synthetic data has multiple applications across various industries, driven by its ability to provide high-quality, privacy-compliant, and diverse datasets.
In AI and ML, synthetic data plays a crucial role in training models. One of the significant challenges in AI development is data scarcity, where obtaining sufficient real-world data for training is difficult, costly, or impractical. Synthetic data helps overcome this challenge by generating large volumes of data that mimic the statistical properties of real data, thereby enhancing the performance and robustness of AI models. For instance, autonomous vehicle manufacturers use synthetic data to simulate driving conditions and scenarios that would be rare or dangerous to capture in real life, thus improving the safety and reliability of their AI systems.
Synthetic data provides an innovative solution for protecting sensitive information in data privacy and security. Organizations can conduct testing and development by creating synthetic versions of real data without risking exposure to personal or confidential information. This is particularly important in industries like healthcare and finance, where data privacy regulations such as GDPR and HIPAA are strict. Synthetic data allows these sectors to maintain compliance while leveraging data for analytical and developmental purposes. For example, banks can use synthetic data to test fraud detection algorithms without exposing actual customer information, thereby balancing innovation with privacy.
Simulation and modeling are other vital areas where synthetic data significantly impacts. Synthetic data can accelerate product development and testing by providing realistic simulation datasets. This reduces the reliance on physical prototypes and allows for extensive testing under various conditions, which can be time-consuming and expensive if done with real-world data. In industries such as aerospace, synthetic data enables the creation of virtual environments where new products can be tested rigorously before any real-world implementation, thereby saving costs and reducing time to market.
The healthcare and pharmaceutical industries are at the forefront of adopting synthetic data due to its significant benefits in addressing data privacy and accessibility challenges. Synthetic data can be used to train AI models on medical imaging, enabling the development of advanced diagnostic tools to identify diseases such as cancer from radiology scans. Additionally, synthetic data facilitates personalized treatment plans by simulating patient-specific scenarios without exposing real patient information. This is particularly crucial in clinical trials, where synthetic data can be used to augment real data, ensuring that patient privacy is maintained while still providing robust datasets for research. Synthetic data in healthcare also supports compliance with stringent regulations like HIPAA, making it a valuable tool for enhancing patient care and advancing medical research.
In the financial sector, synthetic data is employed for various critical applications, including fraud detection, credit scoring, and risk management. Financial institutions face significant challenges accessing and utilizing customer data due to strict privacy regulations such as GDPR. Synthetic data provides a solution by enabling these institutions to create realistic datasets that replicate the statistical properties of real customer data without compromising privacy. This allows for extensive testing and validation of financial models, improving their accuracy and reliability. Furthermore, synthetic data helps financial institutions maintain compliance with data protection laws while still leveraging the power of data analytics to enhance their services and mitigate risks effectively.
The insurance industry utilizes synthetic data for underwriting, claims processing, and fraud detection applications. Synthetic data enables insurers to create diverse and comprehensive datasets that enhance the accuracy of predictive models. This, in turn, improves decision-making processes across various departments. Using synthetic data, insurance companies can share data internally without exposing sensitive customer information, thus ensuring compliance with privacy regulations. Additionally, synthetic data supports the development of more robust fraud detection systems by providing varied scenarios for model training and testing, ultimately leading to better risk assessment and management.
In retail and e-commerce, synthetic data is leveraged to analyze customer behavior, manage inventory, and develop personalized marketing strategies. By generating realistic datasets that mimic customer interactions and preferences, retailers can gain valuable insights into purchasing patterns and market trends. This enables more effective inventory management and targeted marketing campaigns that resonate with customers. Moreover, synthetic data allows retailers to test new strategies and technologies in a simulated environment before implementing them in the real world, reducing risks and enhancing decision-making. The ability to create diverse and comprehensive datasets also helps retailers optimize their operations and improve customer satisfaction.
Synthetic data significantly benefits the automotive and manufacturing industries, particularly in developing and testing autonomous driving systems and predictive maintenance models.
Autonomous vehicles require extensive data to navigate diverse driving conditions safely. Synthetic data provides the necessary breadth and variety of driving scenarios, including rare or dangerous situations that are difficult to capture in the real world. This helps improve the safety and reliability of autonomous driving systems.
Synthetic data supports predictive maintenance by simulating equipment failures and operational conditions in manufacturing. This enables early detection of potential issues and reduces downtime, leading to more efficient production processes and cost savings.
The public sector and smart cities increasingly utilize synthetic data for urban planning, traffic management, and public health monitoring. Synthetic data allows governments and municipalities to simulate various scenarios, such as changes in traffic flow or the impact of new infrastructure projects, without compromising citizen privacy. This helps make informed decisions that enhance public services and improve the quality of life for residents. In public health, synthetic data can enable monitoring disease outbreaks and evaluating public health interventions without exposing sensitive health information, ensuring privacy while facilitating better health outcomes.
One of the main challenges of synthetic data is ensuring its accuracy and authenticity. Despite advancements in techniques like GANs and statistical modeling, creating synthetic data that perfectly replicates the complexity and nuances of real-world data still needs to be solved. For instance, synthetic data for autonomous driving must account for countless variables and rare events, making it challenging to generate comprehensive and realistic data for training AI models. Inaccurate synthetic data can lead to flawed models, reducing their effectiveness and reliability in real-world applications. Ensuring high fidelity in synthetic data requires continuous refinement of algorithms and validation against real-world datasets, which can be resource intensive.
The ethical considerations surrounding synthetic data are significant and multifaceted. One major concern is the potential for bias in synthetic data. If the real data used to train models for generating synthetic data contains biases, these biases can be perpetuated or even amplified in the synthetic datasets. This can lead to unfair or discriminatory outcomes in AI applications, particularly in sensitive areas like hiring, lending, and law enforcement. Furthermore, there is the risk of misuse of synthetic data, such as creating deepfakes or synthetic identities, which can have severe societal implications. Ethical guidelines and rigorous oversight are essential to mitigate these risks and ensure the responsible use of synthetic data. Stakeholders must work together to develop standards and best practices that address these ethical challenges.
Convincing organizations and stakeholders of the validity and utility of synthetic data remains a significant challenge. Many companies are accustomed to relying on real-world data and may be skeptical of synthetic data’s accuracy and representativeness. This skepticism is often rooted in experiences with earlier versions of synthetic data, which were less complex and more prone to inaccuracies.
Overcoming this challenge requires demonstrating the tangible benefits of synthetic data through successful case studies and real-world applications. Moreover, education and awareness initiatives are crucial to informing stakeholders about the advancements in synthetic data technology and its potential to solve pressing data-related issues.
While synthetic data offers many advantages, it is not a magic formula and often needs to be integrated with real-world data to maximize its utility. Hybrid datasets that combine synthetic and natural data can provide the best of both worlds, enhancing the robustness and adaptability of AI models. However, integrating these two types of data presents technical and methodological challenges. Ensuring that synthetic data seamlessly complements real data requires complex data engineering and validation techniques. Additionally, the integration process must address discrepancies and ensure the combined dataset maintains high quality and relevance.
Navigating the complex landscape of data privacy regulations is another critical consideration for synthetic data. While synthetic data can help organizations comply with regulations such as GDPR and CCPA by eliminating the use of real personal information, it must still be generated and used in ways that adhere to these laws. For instance, ensuring that synthetic data does not accidentally re-identify individuals or contain traces of real data is crucial for maintaining compliance. Organizations must implement robust data governance frameworks and conduct regular audits to ensure their synthetic data practices align with regulatory requirements.
Synthetic data represents a revolutionary shift in how organizations approach data-driven innovation. By offering high-quality, privacy-compliant, and diverse datasets, synthetic data addresses many of the limitations associated with real-world data, such as privacy concerns, data scarcity, and high data collection costs. Its vast and impactful applications span AI and machine learning, data privacy and security, and simulation and modeling. Industries such as healthcare, financial services, insurance, retail, automotive, and the public sector already benefit from synthetic data, leveraging it to enhance decision-making, improve operational efficiency, and drive innovation.
The future of synthetic data looks promising, with ongoing advancements in data generation techniques and increasing recognition of its value across various sectors. By responsibly and ethically leveraging synthetic data, businesses can unlock new opportunities for innovation, enhance their AI and machine learning capabilities, and maintain a competitive edge in an increasingly data-centric world.
As such, partnering with experienced providers like rinf.tech can help organizations navigate this complex landscape, ensuring they harness the full potential of synthetic data for their data-driven projects and initiatives.
Let’s talk.
Everyone Wants AI, but Data Orchestration Comes First Enterprise AI conversations often start in the wrong place. They focus on models, talent, or investment levels,

rinf.tech’s Databricks Partnership for Data & AI Platform Engineering in Regulated Enterprises Enabling Governed, Production-Ready Data & AI Operations rinf.tech customers gain access to production-ready Data and AI platforms,

The Biggest Data Privacy Risk in 2026 Comes From Helpful Employees As AI becomes a daily productivity tool, data privacy risk is increasingly created inside